AI Writes Code That Already Exists: Avoid Duplicate Work

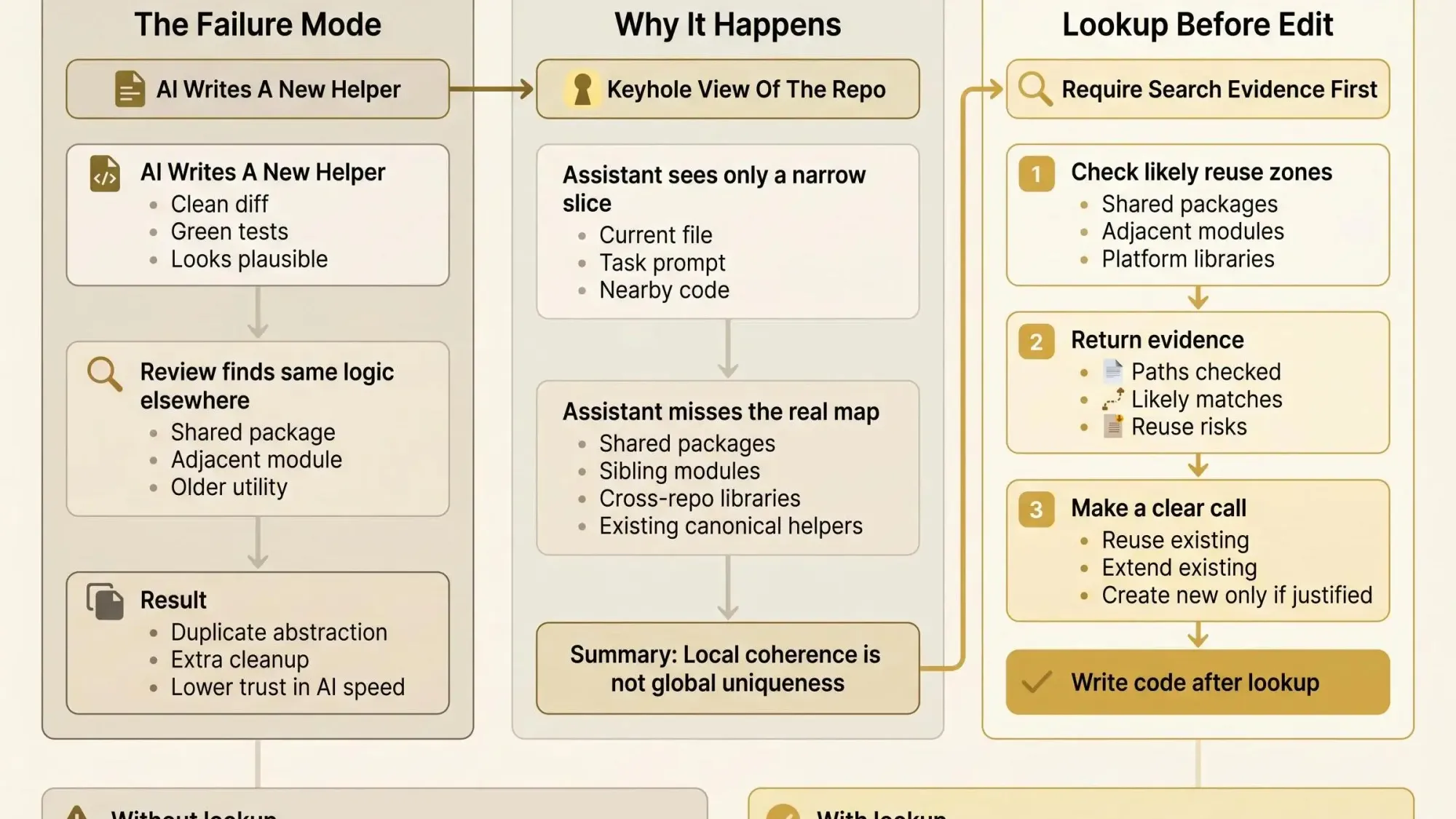
AI writes code that already exists when the repo shows up as a keyhole, not a map. You get a clean diff, green tests, then review finds the same helper two folders over.
For teams using Claude Code, Cursor, or Codex on multi-module codebases, what matters isn't prompt polish. That means lookup before edit, with search evidence, dependency context, and a clear reuse call.
Start here:
- Check shared packages and adjacent modules before any new helper appears.
- Make the assistant list paths checked, likely matches, and what breaks if it reuses one.
- Do that, and you stop merging tidy duplicates.
The Failure Mode Every AI-Assisted Team Recognizes
You ask Claude Code, Cursor, Codex, or another MCP client for a small feature. It writes a tidy helper, wires it in, tests pass, and the diff looks clean enough. Then review starts and someone spots the same logic sitting in a shared module two directories away.
That moment gets old fast.
You don't get annoyed because the code is broken. You get annoyed because it works and still creates cleanup. Now someone has to unwind it, compare behavior, decide which version is canonical, and explain in review why a perfectly plausible abstraction shouldn't exist.
That creates a specific kind of fatigue:
- review comments that keep repeating the same point
- extra test surface for logic you already had
- creeping clutter in modules that used to have a clear center
- less trust in AI speed because speed keeps leaving residue
We're not trying to slow the assistant down or turn every task into repo archaeology. The goal is simpler than that: make reuse cheaper than invention.
When an assistant can't see the real shape of the codebase, it invents in the dark.
That's the whole problem. And once you see it that way, a lot of the frustration stops looking mysterious.

Why AI Writes Code That Already Exists
The reason is mostly structural. Models are good at producing locally coherent code from the files, tests, and prompts you gave them. They are not good at proving that a helper is globally unique across a repo, much less across many repos they only partly saw.
In practice, the assistant usually sees:
- the current file
- a failing test or feature request
- a narrow slice of surrounding code
- maybe a few files it pulled in during the session
What it often does not see is the boring but important stuff: older shared packages, parallel implementations in adjacent modules, half-forgotten platform libraries, or the util directory with the slightly wrong name that already solved this two years ago.
This gets worse under common conditions:
- multi-module monorepos
- multi-repo systems with shared internal libraries
- older codebases with inconsistent naming
- teams moving fast enough that they ask for code before they ask for map-reading
So when people ask why ai writes code that already exists, the answer usually isn't that the model is stupid. It's that the repo is only partially visible at generation time.
That's an important framing shift. Duplicate work is often a context problem, not an intelligence problem.
A model can be very strong and still produce a second email validator if the first one lived in shared/string/rules.ts, the task started in apps/billing/forms, and nobody required a lookup step before generation. We've seen teams blame the model when the actual failure was operational: they let it code before it searched.
Not All Duplicate Work Looks the Same
If you only look for copy-paste clones, you'll miss the version that matters most in AI workflows. The assistant often rewrites the same behavior in different words.
There are three buckets worth separating.
Exact, near, and semantic duplicates
- Exact duplicates - copied or lightly edited blocks
- Near duplicates - same structure, renamed variables, minor control-flow changes
- Semantic duplicates - different syntax, same job
Semantic duplication is where teams get burned. The assistant rewrites validation, formatting, retries, serialization, pagination, or error mapping with different names and slightly different method choices. The output looks original. The behavior isn't.
Simple search won't catch much of this. If one module validates email with includes("@"), another uses a regex, and a third wraps both in isDeliverableEmail, text search gives you fragments, not confidence.
A few examples that show up constantly:
- Email validation implemented with
includes, regex, index checks, and helper wrappers in different modules - CSV export logic rebuilt inside a page component even though a shared export package already exists
- Retry logic reappearing in service clients across repos with slightly different timeout defaults
- Request mapping duplicated as "format", "normalize", "toPayload", and "buildBody"
Research on code generation has split repetition into character-level, statement-level, and block-level patterns. That's useful, but the operator lesson is simpler: there isn't one duplicate failure mode. There are many, and AI tends to generate the kind that looks fresh enough to survive first glance.
Different syntax can still be duplicate architecture.
That's the line reviewers need in their head.
The Real Cost Is Bigger Than a Few Extra Lines
It's tempting to treat this as cosmetic. A few extra helpers, a few comments in review, no big deal. That reading doesn't survive contact with a busy codebase.
The cost shows up in places engineers already feel:
- more code to review
- more logic to test and maintain
- drift between similar implementations
- bug fixes applied to one copy but missed in the other
- slower refactors because nobody knows which path is the real one
And the numbers get ugly faster than people expect. Field reports have found dozens of semantic duplicate patterns spread across many files, with thousands of context tokens wasted on repeated logic. One reported consolidation cut duplicate-pattern tokens from 8,450 to 1,200 - about an 85 percent drop. Large code quality reporting has also shown a sharp rise in duplicated blocks in AI-assisted code, including a fourfold increase in clone-related patterns over recent years. Empirical work on commercial code generators has found clone rates reaching 7.5 percent for exact and renamed clones.
Those aren't abstract metrics. They affect day-to-day work.
If you have three retry wrappers with slightly different status-code handling, an incident turns into archaeology. If auth header construction is duplicated across services, one patch doesn't fix the platform. If you keep adding local utilities, the assistant spends more of every future session reading noise.
Passing tests don't prove the new abstraction belongs in the repo. They prove it works in the slice you exercised. That's not the same standard.
And there's a security angle people underweight. Duplicate permission checks, auth flows, or request-signing code create inconsistent risk. The bug isn't just duplicated code. It's duplicated responsibility.
Why Grep, Memory, and Code Review Are Not Enough
Most teams already have defenses. They're just arriving too late.
Grep helps when you know the name of the thing you're looking for. Repo search helps when naming is consistent. Human memory helps when the system still fits in one person's head. None of those conditions hold for long.
The failure pattern is predictable:
- The assistant generates a plausible helper in seconds.
- Nobody can immediately prove whether a shared version exists.
- The code gets tested, discussed, maybe polished.
- Review finally catches the overlap.
- Everyone pays for work that should never have started.
Most code review tools catch duplication after the work is already written. For AI-assisted development, that's backwards.
Reviewers are being asked to detect global duplication through a PR-sized window. That was already hard before AI made helper creation nearly free. It's worse in multi-repo environments, where the duplicate may live outside the repo under review.
A two-minute neighborhood read often prevents a day of thrown-away work. We've seen that pattern enough times to treat it as operating procedure, not advice.
The cheapest fix is before the first edit.
A Better Default: Require Lookup Evidence Before New Code
Teams need a simpler rule: no new utility, validator, formatter, or integration helper until the assistant shows what it searched.
That's not heavy process. It's just proof of due diligence.
The pre-edit lookup workflow
Ask the assistant to do this before it writes code:
- Identify the domain keyword for the task.
- Inspect the local directory and adjacent modules.
- Search shared packages and cross-cutting libraries.
- Return the paths checked.
- Classify the result as reuse, extend, or genuinely new.
Good output should include:
- candidate existing implementations
- why they do or don't fit
- blast radius if you reuse or change one
- a short reason for creating something new if no fit exists
You can require a compact artifact in the prompt or PR description:
Checked paths:- packages/shared/validation- packages/platform/export- apps/billing/lib- services/customer-client/src/retryDecision:- Extend existing export helper in packages/platform/exportAffected dependencies:- billing-web- reporting-workerDuplicate risk notes:- Found similar CSV field mapping in apps/billing/pages/export.tsx- Remove local mapping after reuseLinting and testing still matter. They check correctness after code exists. The open source AI Code Quality Framework is useful on that side. But correctness guardrails do not replace structural lookup before generation.
What Good Duplicate Prevention Looks Like in Real Workflows
This has to work inside the tools people already use. Otherwise it becomes policy theater.
Claude Code inside a monorepo package
You're adding a feature in packages/billing-ui. Before any edit, have the assistant search the package, then sibling packages, then shared libraries. Ask for file paths and a reuse recommendation.
If the logic involves validation or formatting, default to suspicion. Those are high-duplication zones.
Suggested prompt pattern:
Before writing code, search for existing implementations for invoice formatting and validation.List relevant files in this package, sibling packages, and shared modules.Explain whether we should reuse, extend, or create new code.Then propose the change.Cursor-assisted refactor touching shared utilities
Refactors are dangerous because the assistant can "clean up" by creating a new helper that only looks cleaner locally. Require it to identify the current canonical path first, then show dependents before extracting anything.
If it can't name downstream consumers, it doesn't understand the move yet.
Codex in a service repo with platform dependencies
Service repos often hide platform duplication because the reused code lives elsewhere. The assistant should check service-local code and platform libraries before inventing request mapping, retries, auth headers, or pagination wrappers.
This is where local repo search runs out of road.
PR review with a suspiciously neat helper
If a helper looks right but oddly generic, ask four questions before merge:
- Where else did we search?
- Is there already a shared version in another package or repo?
- Should this extend an existing abstraction instead?
- If this is truly new, why will it stay unique?
This workflow doesn't kill velocity. It removes false starts. Teams feel the difference by the second afternoon because fewer "looks good, but..." reviews make it to the thread.
The Tooling Stack: What Each Layer Can and Cannot Catch
No single layer solves this. You need a stack, and you need to know which layer is prevention versus cleanup.
Fast text and token clone tools like jscpd, dupl, and goclone are good at exact and near duplicates. They're useful in CI for copy-paste drift. They won't reliably catch semantic duplication.
Rule-based tools like Semgrep help when you already know the repeat offenders. They're good for patterns like repeated validation paths, error wrappers, or unsafe iteration habits. The limit is obvious: you only catch what you've encoded.
AST and similarity-based analysis gets closer to semantic overlap. It can spot helpers that differ in variable names or method choices but still do the same job. That matters in AI-generated code because rewritten syntax is common.
Platforms like SonarQube help with ongoing visibility. That's useful for trend detection and cleanup planning. It still happens after code exists.
A practical way to think about the layers:
- Clone detection - catches obvious repeats
- Pattern rules - blocks known bad habits
- AST or similarity analysis - finds rewritten equivalents
- Review-time and cross-repo analysis - catches spread across packages and services
- Architecture-aware context - prevents duplication before generation
That last layer changes the economics. Detection after the fact matters, but prevention before generation is where AI workflows gain the most.
Why a Codebase Graph Changes the Quality of AI Output
Structural awareness isn't mystical. It means the assistant can see which modules depend on which, where behavior already lives, what code is dead, and what gets touched if a shared function changes.
Without that, the assistant keeps producing local answers. Local answers are often wrong at system level.
This matters more as the environment gets messier:
- monorepos with shared packages
- service platforms with repeated integration code
- legacy systems with inconsistent names and unclear ownership
A codebase graph gives the assistant a map instead of a flashlight.
At Pharaoh, this is the problem we focus on. We map software architecture into a knowledge graph that AI coding assistants can use through MCP, so they can surface dependencies, existing code, blast radius, and dead code before edits happen. If you're using Claude Code, you can add a codebase graph via MCP in about 2 minutes at pharaoh.so.
The important point isn't the product pitch. It's the operating model. Better output comes from better repo legibility, for humans and machines. Not from asking the assistant to "be smarter" while hiding half the system from it.
Confidence comes from visibility, not optimism.
That's usually the missing piece.
A Practical Rollout Plan for Engineering Teams
Don't start with a grand policy. Start where duplication already hurts.
Focus first on:
- utilities
- validation
- API clients
- export logic
- request mapping
- retry and error wrappers
Then put a few lightweight rules in place.
Team policies that don't get ignored
- Every AI-authored PR lists paths checked
- Every new shared helper explains why an existing one wasn't reused
- Duplicate fixes should prefer consolidation over adding a sixth variant
Then add the detection layers that fit your size.
A small repo with low churn may only need better prompts and CI checks for exact or near clones. A monorepo with frequent AI edits usually needs stronger pre-edit lookup and architecture context. Multi-repo platform teams benefit from cross-repo visibility earlier in review, before drift spreads.
Track a few things for one sprint:
- count of duplicate helper names
- near-duplicate patterns in high-churn modules
- percentage of PRs introducing new utilities
- review comments pointing to existing implementations
- token reduction after consolidating noisy modules
You don't need perfect measurement. You need a signal strong enough to change behavior.
One practical move you can make this week: pick the last five AI-authored PRs and mark every new helper as reuse, extension, or unnecessary invention. That audit will tell you where your process is thin. Usually fast.
Conclusion
When ai writes code that already exists, the root cause is usually missing structure and missing context, not lack of model talent.
The working model is straightforward:
- detect duplicates at more than one level
- require search evidence before new code
- prefer prevention before PR review
- give the assistant architecture-aware context when the codebase is too large to fit cleanly in a prompt
If you want an immediate next step, audit one recent AI-authored PR and look for logic that already existed elsewhere. Turn what you find into a pre-edit lookup checklist. If your team uses MCP clients, consider adding a codebase graph so the assistant can see dependencies and existing implementations before it starts writing. Pharaoh does this automatically via MCP at pharaoh.so.
Fewer invented helpers. Cleaner reviews. Faster reuse decisions.
That's the win.