Code Dependency Graph MCP Server: Map Relationships Fast
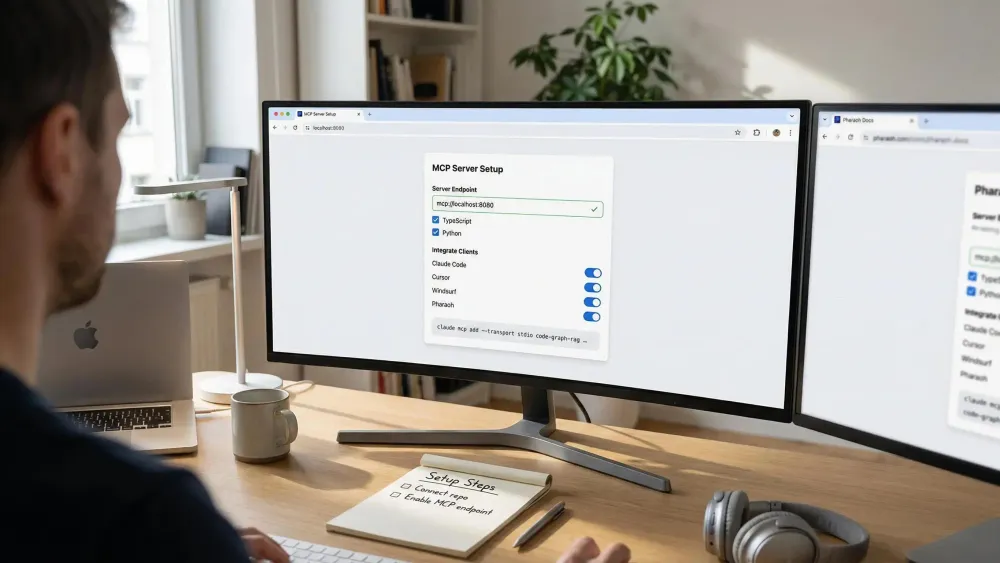
A code dependency graph mcp server turns your codebase into a queryable map of modules, functions, and dependencies, making it easier for AI coding tools like Claude Code, Cursor, or Windsurf to see how everything fits together.
No more duplicate code or broken links caused by agent guesswork.
Instead, your AI tools get clear, structured context so every answer is fast, accurate, and safe.
With code dependency graph MCP servers, your entire architecture becomes instantly searchable and actionable for agent-driven development.
Why Code Dependency Graph MCP Servers Matter for AI-Driven Development
Let’s get real. If you run agents like Claude Code or use Copilot, you’ve seen it: code duplication, invisible breakage, and logic that never connects. The root problem? Your codebase is a maze, and your AI agent doesn’t have the map. Faster shipping means faster surprises—usually bad ones.
How can you break this cycle, hit scale, and trust your tools? Check these real pain points to see if a code dependency graph MCP server belongs in your stack:
- No more code blind spots: Conventional AI tools scan files in chunks. They can miss relationships. You risk “fixes” breaking endpoints or missing unused functions. When your codebase balloons, so do the blind spots.
- Zero guesswork for agents: Queryable, deterministic graphs mean AI gets answers from hard structure, not token-limited samples. This isn’t magic, it’s reproducibility powered by facts.
- Instant blast radius insight: You’ll know, before clicking merge, how a change ripples through your system. That’s safety you can measure.
- Built for how you actually code: Most tools treat code as words or lines. Graph MCP servers treat it as architecture. That means smarter onboarding, safer refactors, and actionable context for every query.
- Security and compliance in reach: Agents pull structural data, not full source. You unlock new ways to audit, isolate, and control what AI can access—huge for regulated teams and growing projects.
When you hand your agent an architectural map instead of a pile of text files, broken code and surprise bugs start disappearing.
At Pharaoh, we see the impact when solo devs and tight teams get this context: agent deployments run up to 60% faster, and redundant work drops. You spend less time fighting your own codebase, and more time shipping.
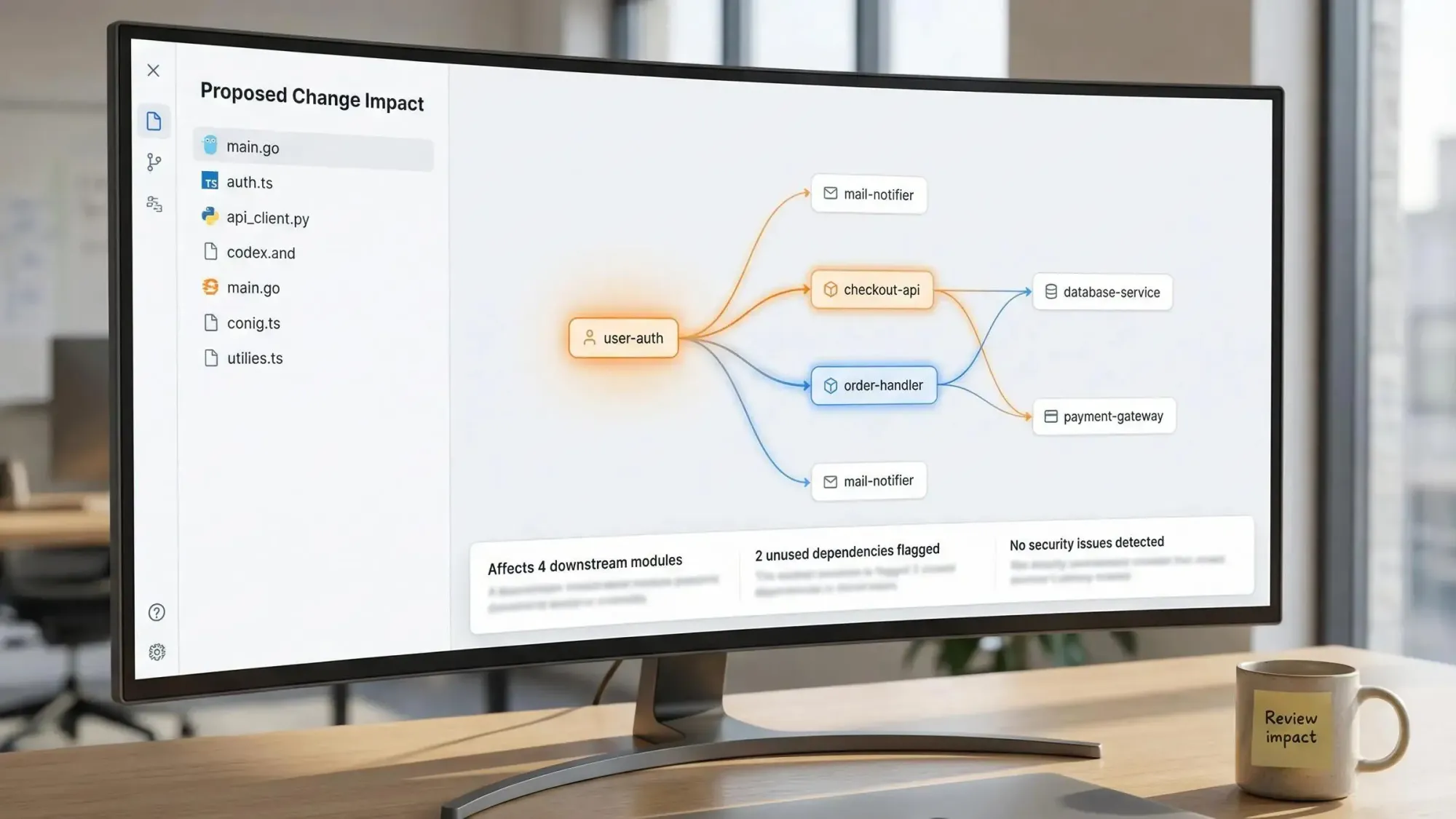
What Is a Code Dependency Graph MCP Server?
A code dependency graph MCP server transforms your codebase into a structurally mapped knowledge graph. Instead of parsing files by hand or relying on AI guesswork, you get a precise, up-to-date model of all your code relationships—queryable on demand.
MCP: Your Fast Lane to AI Integration
The Model Context Protocol (MCP) acts as connective tissue. It lets agents like Claude Code, Windsurf, and Cursor ask your server where functions live, what imports what, and how modules tie together—using standard, well-defined APIs.
What the Graph Knows
A modern graph MCP server does more than show you files:
- Maps classes, modules, imports, function calls, endpoints, environment variables, and even cron jobs.
- Makes cross-language queries feel natural, whether it’s TypeScript on frontend or Python in backend.
- Answers questions like “What will break if I update this package?”, “Is this endpoint really used?”, “Where’s the dead code hiding?”
Because it builds from deterministic parsing, the output is reproducible and safe for automation.
The real win: agents operate with architectural truth, not hope or token budgeting.
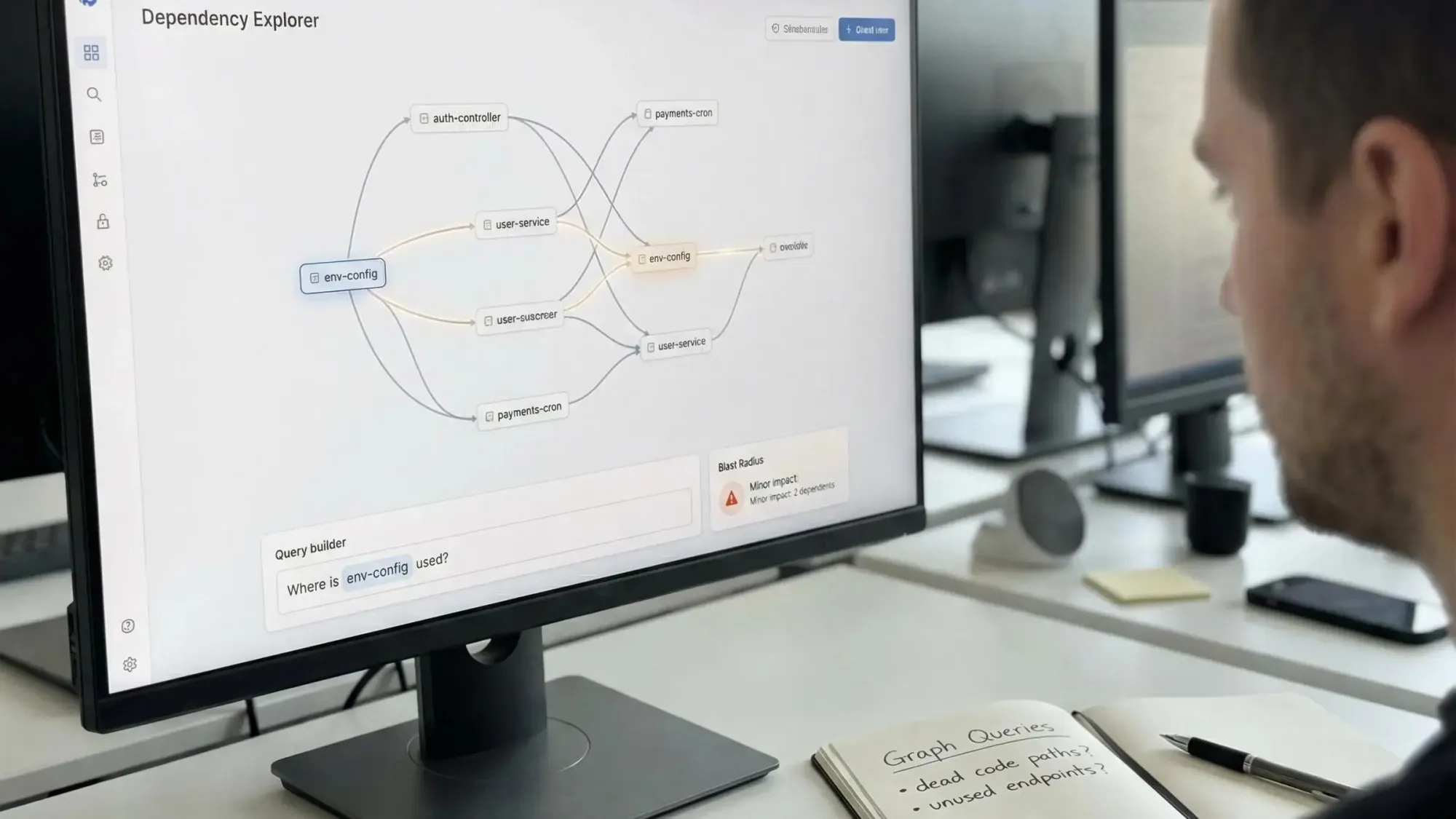
Key Components and Architecture of Code Dependency Graph MCP Servers
Self-respecting developers want clarity and reliability from their automation stack. Let’s break down what actually powers a code dependency graph MCP server.
The Essential Building Blocks
- Parsing engine: Tree-sitter enables robust AST (Abstract Syntax Tree) parsing, so you get accurate, language-agnostic slices of your code—no fuzziness, no drift.
- Graph database backend: Neo4j-style graphs store all your code’s relationships. These aren’t just files—they’re nodes, edges, and connections ready for deep querying.
- MCP connection layer: This forms the bridge between your code graph and any AI client. Standard APIs. Secure access. No heavy integration work.
What You Actually Get Mapped
Every server worth your time will track:
- Functions, classes, interfaces, and module boundaries.
- Imports, exports, internal and external dependencies based on manifests (think pyproject.toml).
- Runtime touchpoints like endpoints, cron jobs, and env vars—critical for agent planning.
Smart Sync and Updates
With automated propagation, file changes kick off instant re-indexing. No stale state. The server stays current during every CI push, branch, or commit.
Code parsing is deterministic: what you see in the graph is what’s live in your code. No surprises.
Setting Up and Integrating a Code Dependency Graph MCP Server
You want speed, clarity, and as little friction as possible. Here’s how easy integration should work.
The No-Guess Setup Approach:
- Connect your GitHub repo. The right server detects your stack: TypeScript, Python, or both.
- Auto-parse and map your project into a graph instantly.
- Set your MCP endpoint—now Claude Code, Cursor, and other agents have instant architectural insight, not partial file snippets.
Integration Fast-Lane
You get a toolkit built for real workflows:
- Use query tools directly from your agent or IDE.
- Enable auto reindexing with webhooks on branch merges.
- Get granular: limit your agent’s reach by scoping permissions or setting up sandboxed testing zones.
Reference: Want to see it in action? The Pharaoh platform walks you through this with zero-config trials, letting you ship proof-of-concepts right out of the gate.
The first time you run query_graph and get a precise map of functions, dependencies, and endpoints, the productivity jump is obvious.
Core Use Cases and Workflows for Developers and AI Agents
You’re shipping fast. But are you confident? A code dependency graph MCP server isn’t theoretical—it directly powers the workflows you need.
Real-World Workflows That Move the Needle
- Onboarding at speed: New repo? Run get_codebase_map to get a real architectural overview in one command. No more clicking through every folder.
- Refactoring with zero fear: Use blast radius tools to see the true impact of a code change before you merge. Safer pushes every time.
- Function search, zero guess: Don’t repeat yourself (DRY) is real when you can instantly scan for duplicates with search_functions or semantic_search.
- Reachability with proof: Use check_reachability to confirm every endpoint, cron job, or feature is plugged into the runtime—and not lost in the weeds.
- Dead-code cleanup: Get_unused_code spots unreachable or forgotten logic, so you can cut fat proactively.
For Cairo, solo founders, and AI-native teams, these aren’t wishlist tools. This is the architecture-first way to ship without regrets.
The best agent workflows chain these tools: plan a refactor, map the impact, run a search, propose a diff—and have every step backed by the certainty of your own code’s architecture.
Inside the Toolbox: What Features and Intelligence Can You Expect?
When you work with a real code dependency graph MCP server, you get a suite of high-impact tools—not gimmicks, but fast paths to clarity and results. Every feature exists to boost your agent’s IQ and your team’s peace of mind.
Unlock a Toolkit Made for Builders
Here’s what lands in your hands:
- get_codebase_map: Get a one-screen architectural map of your entire codebase in real time. Know where the work is.
- get_module_context: Drop into any module or file and pull its graph—see who calls it, imports it, or relies on it.
- search_functions / semantic_search: Cut duplication at the source. Instantly search for logic by name, type, or fuzzy description and see results with source links.
- get_blast_radius: Preview the impact of any planned change. No more edge-case surprises.
- check_reachability: Verify any endpoint, cron job, or function is truly wired to execution paths.
- get_unused_code: Identify dead code fast. Strip bloat, tighten attack surfaces, and deploy only what matters.
Each tool is designed for speed. Graph queries return results in seconds—with reproducible, deterministic context. Your agent avoids the LLM token lottery for almost every operation.
The right tool, armed with graph-native context, instantly turns “where’s that logic?” into “here’s the answer, now move.”
Performance, Privacy, and Reproducibility: What Sets Advanced Implementations Apart?
Today, trust and speed matter as much as raw features. The best MCP servers focus on three things: fast queries, airtight privacy, and reliable, reproducible context.
What Advanced Devs Demand
- Privacy by architecture: Only structural metadata is stored, not your raw code. This means you keep secrets safe, enable tenant isolation, and cut audit headaches.
- Deterministic outcomes: Each parse is reproducible. That’s vital when you need to explain or audit a refactor, onboard new engineers, or trace changes.
- Speed and scale: Tree-sitter paired with a graph DB keeps parsing and querying fast. Most queries finish in a second or two, even in mid-sized repos.
- Cross-language clarity: Unified mapping lets you ask, and answer, questions across TypeScript, Python, and beyond—no special rules for each language.
- Operational discipline: OAuth 2.1 enforces tight access. No overexposure. No open doors for agents. Frequent patches and input validation kill known CVEs before they start.
You gain security, audit trails, and blazing speed—at the infrastructure level, not by accident.
How to Choose the Right MCP Server for Your AI Team
Picking an MCP server isn’t one-size-fits-all. The right choice grows with you, backs your stack, and removes friction at every turn. Here’s our checklist for decision-makers building the future:
- Language support that fits your codebase: TypeScript, Python, and the tools your stack needs—mapped accurately, every time.
- Graph-first integrations: Look for Neo4j compatibility and Cypher-ready querying, so you aren’t locked into one editor or ecosystem.
- MCP simplicity: Get plug-and-play support for Claude Code, Cursor, Windsurf, and your own agent automation.
- Security and sandboxing: Make sure you get tenant-scoped graphs, OAuth, and least-privilege tokens.
- Real-time sync and CI reindex: Don’t settle for lag. The best options re-parse on merges, CI runs, or branch pushes.
- Hosted, self-hosted, or both: Choose what matches your privacy needs and ops budget.
At Pharaoh, we set the pace: deterministic parsing, instant graph insight, 13 essential tools, and integrations across today’s most popular AI coding workflows. Free to start and built for builders who want to ship, not just search.
Getting Started: First Steps to Mapping Your Code Dependencies
You want instant value. Here’s how you can go from zero to mapped in a few focused moves.
Practical Launch Plan
- Pick your top pain point: Are you onboarding or prepping a big refactor?
- Fire up a code graph: Start with Pharaoh’s free trial—connect a repo, auto-map it, and test the tools.
- Run your first queries: Use query_graph or get_codebase_map to see your structure. Spot blind spots, then dig deeper.
- Enable hooks and CI triggers: Automate reindexing so the map always matches your main branch.
- Stay safe: Test edits in a sandboxed branch with strong approval flows and OAuth-based keys.
Start small, then scale once you see results. Most teams hit instant ROI by running blast radius checks before that first risky merge.
Conclusion: Unlocking Confident, Blueprint-Driven Development
Move from risk to readiness by giving your agents the structure they need—and your team the answers they crave. Code dependency graph MCP servers transform query chaos into blueprint-driven confidence.
Start mapping with Pharaoh, see your real architecture, and ship smarter. Fast setup, always-on insight, and fearless development—this is what AI-native teams deserve.