How to Build Codebase Context for AI Agents in Your Repo
Codebase context for AI agents is now the key difference between an AI teammate that makes fast, safe changes and one that breaks your repo without warning.
You’re not alone if you’ve lost time to duplicate functions, silent errors, or code that rewrites itself into chaos.
We’ve created a practical guide for developers who need to:
- Build true codebase context for AI agents, not just token dumps
- Integrate graph-backed repo maps with tools like Claude and Copilot
- Prevent costly regressions and ship with system-level confidence
Understand Why Codebase Context for AI Agents Matters
If your AI agent doesn't deeply understand your codebase, it fails you. Developers hit the limit every day: duplicate helpers, random breakages, wasted token spend, and brittle AI-driven edits that miss critical connections. You want speed and safety. You need structure, not just more LLM context.
Problems That Bite Without Real Context:
- Blind changes: AI duplicates logic, breaks imports, or forgets cross-module links because it never sees the full picture.
- Bloated token costs: These “just dump it all” strategies burn tokens and time, but return patchy, partial answers.
- Debugging hell: An incomplete context means anxiety about hidden breakage, more invisible bugs, and slower merges.
- LLM context is not enough: Even big token windows can't solve “architectural amnesia” if you don’t provide structure.
We treat context engineering like disciplined architecture. AI agents need what humans need—explicit blueprints, not random docs.
Context engineering isn’t about cramming in more data; it’s the discipline of giving your agents exactly what they need to act with accuracy and confidence.
Recognize the Limitations of Blindfolded and Incomplete Context
Too many agent stacks process code as files or blobs of text, not as an architecture. This causes them to trip over the same edge cases, session after session.
Where Flat Context Strategies Break Down
Flat retrieval, vectors, and big context files often promise the world, but real-life repo challenges trip them up fast.
Typical Flat Context Failure Modes:
- Lost connections: File-by-file agents miss private callers and orphan endpoints, leaving zombie code paths active.
- Duplication and drift: Functionality gets copy-pasted because agents miss shared helpers buried across the project.
- AGENTS.md pitfall: Collating docs offers, at best, tiny gains (ETH Zurich found only a 4% upside, with bigger inference bills).
- LLM memory gaps: Agents struggle with “lost in the middle” even in massive context windows, missing key links mid-stream.
These approaches don’t just create extra work—they quietly leak bugs into production.
If your agent keeps breaking things you thought it understood, chances are you’re relying on the wrong kind of context.

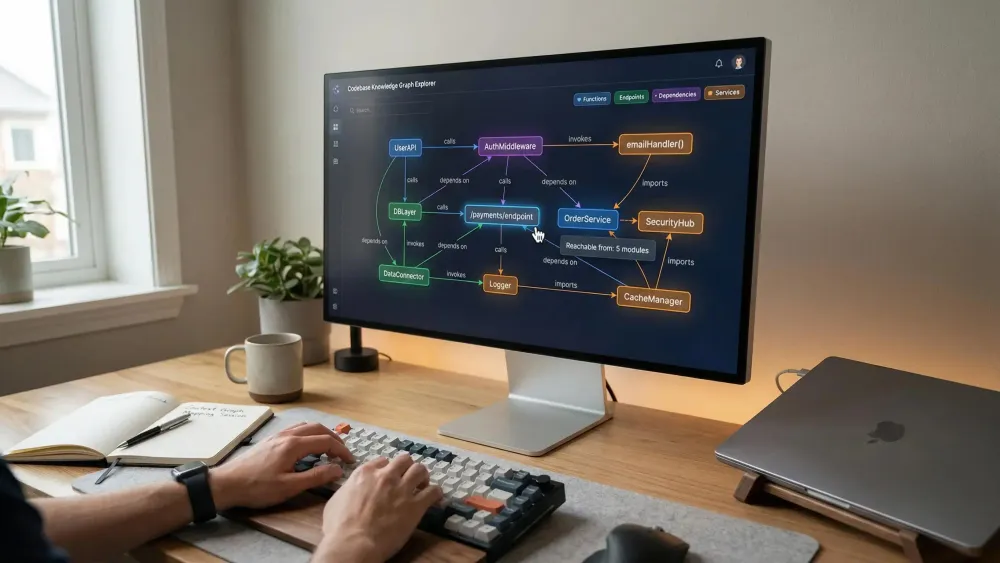
Map Your Repo as a Knowledge Graph: The Foundation for Precise Agent Action
Giving your AI agents a graph, not just a pile of files, means every relationship—imports, callers, test targets, dependencies—is explicit and navigable. Now, agents can reason at the architecture level, not just the file level.
What Actually Gets Mapped (and Why):
- All important modules, files, and functions. Make every entry point and helper discoverable and queryable.
- Dependencies and cross-file imports. AI agents see which changes cascade where.
- HTTP endpoints, DB calls, environment variable use, scheduled jobs: all mapped as graph nodes so agents can audit impacts.
- Deterministic parsing with Tree-sitter keeps the facts straight. This eliminates hallucination risk and ensures repeatability.
Here’s where Pharaoh comes in. Pharaoh auto-converts your TypeScript or Python repo into a Neo4j knowledge graph. It handles module mapping, dependencies, endpoints, scheduling, and environment variables. Everything’s orchestrated for real, fine-grained agent awareness via Model Context Protocol (MCP). Turn it on and instantly unlock structured blast radius, function searches, and reachability insights.
Structural clarity, not token overload, drives fast and safe AI-driven development.
Integrate Model Context Protocol (MCP) Endpoints to Supercharge Your AI Agents
When you connect your knowledge graph to your favorite AI tools through MCP, you give each agent superpowers. Instead of blind hunts, your agents fetch direct answers: “What’s the blast radius?” “Who calls this?” “What’s the right helper?” All without chewing up LLM tokens.
Zero-Cost, High-Impact Integrations
You connect once, then agents like Claude, Cursor, and Windsurf gain:
- Instant lookups: Functions, blast radius, cross-repo links—all accessed in milliseconds, not minutes.
- Zero guesswork: Agents fetch deterministically correct module maps and owner lists, not random docs.
- Real-time CI power: Graph data answers preflight checks and informs code reviews—no more review roulette or hidden risk.
- One connection, many clients: Your repo graph serves answers to any compatible agent or IDE, for persistent, low-latency intelligence.
Setting up is simple: wrap your Neo4j graph as an MCP server endpoint. Define endpoints like get_codebase_map, search_functions, or get_blast_radius. Now, every AI client in your ecosystem can call into your codebase intelligence without extra token spend.
When agents get their context from a graph via MCP, every query is deterministic, fast, and costs nothing in LLM windows.
Use Cases: When Codebase Context Transforms Your Workflow
Mapping your codebase context isn’t just academic. It’s mission-critical if you want to refactor, review, and release at speed and scale without guessing.
Where Graph Context Delivers Results
- Confident refactoring: Know the blast radius, see all callers, and never miss a hidden dependency before you commit.
- Dead code demolition: Find and flag unused code and duplicate logic using graph queries, not wild goose chases.
- Fast onboarding: Give new teammates and agents instant queries like “Show me every payments endpoint, callers, and live tests.”
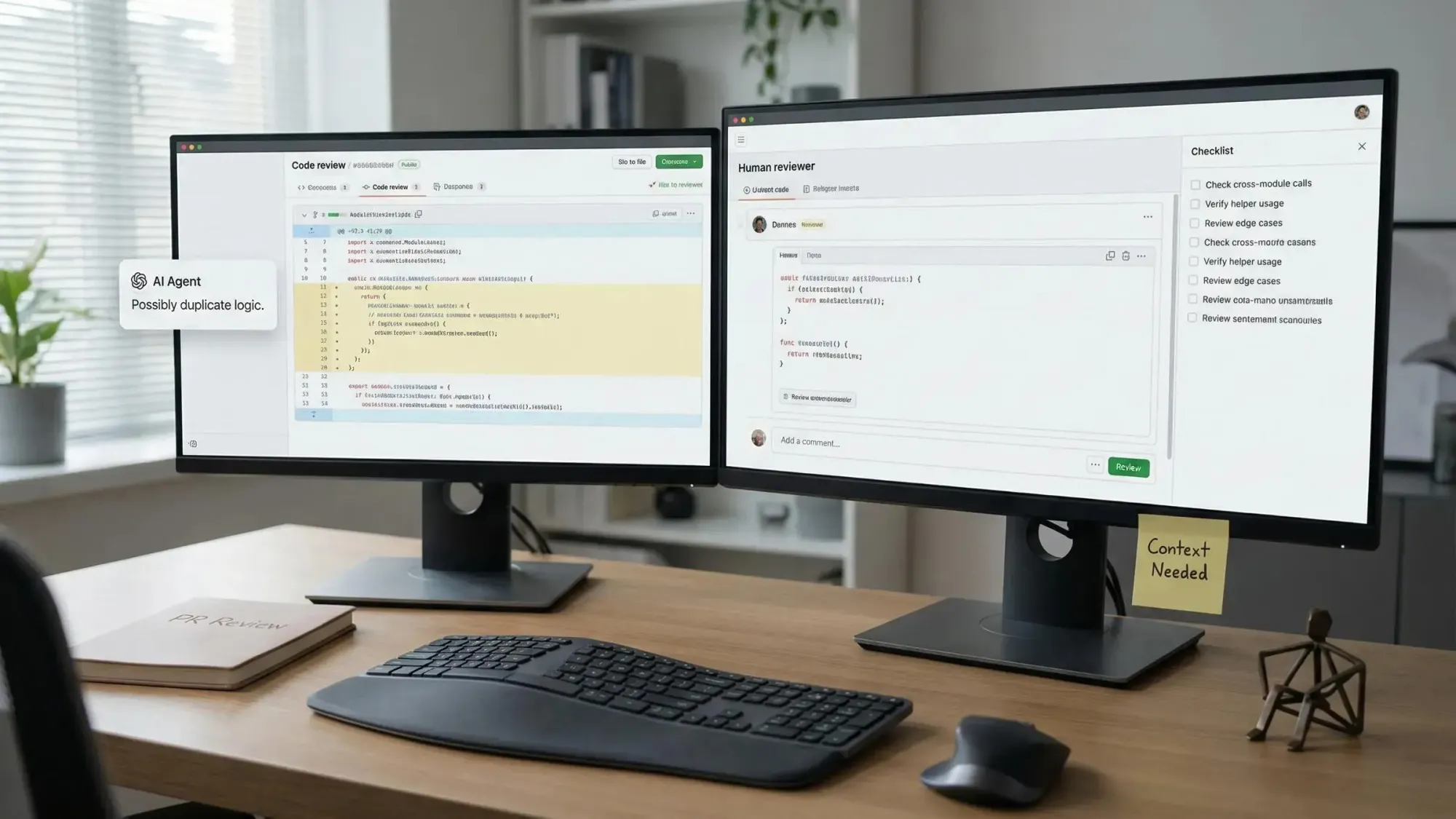
- Automated risk review: Structure-aware context arms PR reviewers with reachability analysis, reducing regressions and CI drama.
- Cross-repo audits: Eliminate code drift and catch duplication, even as teams and codebases multiply.
If you care about speed, safety, and clarity, mapping your codebase context as a live graph isn’t optional—it's the new standard.
Move Beyond Static Context: Dynamic, Zero-Cost Queries for Agents
Prompt engineering hits a wall. Context engineering breaks through. When you build your structure once, then serve it up on demand, every agent action becomes cheaper, faster, and more reliable.
Short, focused context answers let you:
- Cut LLM spend to the bone by offloading graph queries outside the context window.
- Keep context answers reproducible, so the same blast radius, owner list, or function tree surfaces for every agent, no matter who asks.
- Scale with confidence: as your team grows and agents multiply, context is built once and distributed everywhere—no extra cost per agent.
- Automate updates: Parse on every push, keep your context graph fresh, and power a new era of agent-driven development.
Agents equipped with structured, queryable codebase context deliver more value, faster. That’s not a prediction. It’s a fact we see every day.
Best Practices for Building and Maintaining Codebase Context for AI Agents
You want AI agents that deliver, not bots that fumble your features. Best-in-class teams build and maintain codebase context with discipline. It’s not about more data—it’s about accurate, up-to-date, actionable structure for every query.
Rules to Live By for Context Engineering
- Prioritize what’s real: Parse modules, dependencies, and relationships, not just visible code or legacy files.
- Automate graph refresh: Trigger parsing on every push, via webhook or CI action, so your context stays current.
- Always check context before edits: Query blast radius, function usage, dependencies—don’t move fast and break things blindly.
- Continuous improvement: Every time the spec, architecture, or endpoints shift, update your graph. Agents stay aligned with the living code.
- Protect sensitive info: Only store structural metadata. Never leak secrets or raw code through endpoints or visualizations.
- Keep the human in the loop: Trust your system, but require human review and PR Guard checks with every major move.
The agent is only as sharp as its context. Invest in structure and reap exponential returns.
Evaluate Alternatives and Choose the Right Context Approach
Let’s be clear. Not all context solutions deliver the depth and reliability you need as a solo builder or lean team. Here’s what you need to know to invest wisely.
Choosing Your Stack: Pros, Cons, and Best-Fit Use Cases
Vector/Flat RAG Approaches:
- Easy to set up and language-agnostic.
- Good for quick pattern lookups or semantic search.
- Misses explicit relationships; can’t map reachability, blast radius, or transitive risk.
Context Files:
- Fast for small projects; drops off at scale.
- At best, minor accuracy boosts; usually increases LLM token load and inference cost.
Knowledge Graph Backed with MCP (Like Pharaoh):
- Provides deterministic, queryable relationships.
- Automates analysis like blast radius, reachability, and duplication detection.
- Enables zero-cost queries from any MCP-compatible agent.
- Requires one-time setup and ongoing maintenance, but pays off with automation, explainability, and confidence.
The right approach cuts your risk, scales with your repo, and turns every agent query into actionable, absolutely current insight.
Implement Codebase Context in Your Own Projects Step by Step
Ready to make your AI agents smarter, faster, and more aligned with your codebase? Get your context in order with a tight, repeatable workflow.
Quick-Action Guide:
- Connect your repo (GitHub, CLI, etc.) to your chosen context engine.
- Parse and map core architectural elements: modules, dependencies, endpoints, jobs, and env vars.
- Load your graph into Neo4j or a comparable database for structured analysis.
- Expose your context through MCP endpoints (get_codebase_map, search_functions, get_blast_radius).
- Plug your agents (Claude Code, Cursor, GitHub apps) directly into MCP.
- Run blast radius and context queries as PR Guard checks. Automate what you can, but verify before you merge.
With Pharaoh, this workflow is fast and frictionless. We built it for solo engineers and tight teams who need serious repo intelligence without months of setup.
Avoid Common Pitfalls When Providing Codebase Context
You’re building for speed, but these slip-ups slow you down or put your codebase at risk. Learn from teams who’ve gotten burned and avoid these errors by design.
Context Pitfalls: Don’t Let These Slow You Down
- Flooding agents with flat files or bloated context windows. This muddies relevance and racks up your LLM bill.
- Using AGENTS.md or scraped docs as a substitute for actual structure. Agents regurgitate docs instead of making real system decisions.
- Letting your graph go stale. Outdated maps equal incorrect blast radius, missed owners, and broken CI.
- Ignoring cross-module links or downplaying entry point reachability. Blind spots become time bombs.
- Skipping security reviews of MCP endpoints. Protect access, redact raw code, log usage.
Most agent failures trace back to bad or incomplete context. Get ahead of issues with smart, automated hygiene.
See the Results: Developer Confidence, Cleaner Merges, and Faster Delivery
When you run with live, actionable codebase context, the change isn’t subtle. Your AI agents become teammates, not time sinks. You ship faster, fix less, and trust every edit.
Real Gains from Codebase Context You Can Trust
- Confident refactors that reveal every affected function and owner before you touch a line.
- Regression rates drop—anonymous breakage becomes rare in PRs.
- Onboarding times shrink. New developers or agents can map endpoints, find helpers, and identify business logic in minutes.
- PR review stress melts away. Reviews center on logic, not "What did the AI miss?"
- Your future self spends less time firefighting and more time shipping.
Give your team and your agents structure, and you gain velocity, safety, and peace of mind.
Conclusion: Level Up Your AI-Driven Engineering With True Codebase Context
If you want AI agents that actually help you ship, it’s time to move past "just give the model more text." The future belongs to those who equip agents with deep, live, graph-driven repo intelligence.
We built Pharaoh for ambitious solo founders and lean dev squads who know speed only matters when paired with safety. Start structuring your codebase, wiring it for agent clarity, and raising your standards for every AI-driven commit.
Make codebase context your default foundation, not an afterthought.
Your roadmap to cleaner merges, stronger reviews, and fearless shipping starts here. Explore more practical guides and advanced workflows at https://pharaoh.so/blog.
Let’s help your agents—and your team—think bigger, act smarter, and deliver with confidence.