Software Impact Analysis for Safer AI-Assisted Code Changes

AI assistants are fast, but they still miss what hurts: shared interfaces, hidden callers, the old job runner nobody touched in 18 months. Software impact analysis matters because a clean diff can still break code two modules over.
What matters is blast radius, contract changes, and whether code is actually dead (not just quiet). You need enough context to decide before the PR gets momentum.
Before you merge, check:
- signature changes with callers you never opened
- deletions that only look unused from one repo
- tests mapped to affected modules, so production does not teach you first
Why AI-Assisted Development Raises the Stakes on Impact Analysis
You know the pattern. Claude Code or Cursor suggests a tidy refactor, local tests pass, the diff looks clean, and then someone notices it changed a shared interface used by a background job nobody had open. Or it deleted a path that looked dead but was still wired through config in another repo.
That low-grade fear is rational. AI increases throughput, but it does not automatically increase system awareness.
The risk profile changes for three simple reasons:
- AI can generate more change volume per engineer, which means more surface area to validate
- most assistants reason from the files in view, not the architectural graph of the system
- review shifts from checking syntax and style to checking intent, contracts, and blast radius
That last part is where teams get squeezed. A human reviewer can usually tell whether a patch is plausible. It's much harder to tell whether it quietly breaks something two modules away.
Research on agent-generated pull requests points to an uncomfortable truth. In code generation tasks overall, agent PRs introduced fewer breaking changes than human PRs. But that advantage reverses in maintenance-oriented work. Refactors and chore-style changes show notably higher breaking-change rates. High confidence from the agent is not a safety signal on its own, especially when the work looks "safe."
Most review workflows still catch problems after the patch exists. That's backwards.
Software impact analysis is the discipline of asking what else this change can affect before it lands. In AI-assisted workflows, that is no longer a nice extra. It's an operating requirement.

What Software Impact Analysis Actually Means
Software impact analysis is plain language work. You're identifying the likely consequences of a proposed code change across callers, dependencies, tests, interfaces, owners, and runtime behavior.
It's easy to confuse it with adjacent practices. They are not the same thing.
- A diff review shows what changed
- tests show what is currently exercised
- static analysis flags rule violations
- software impact analysis asks what the change can ripple into
That ripple can be checked at different levels. Sometimes symbol-level is enough. Sometimes you need file, module, service, repository, or API contract level analysis because the real risk is not in the edited file at all.
Change impact analysis for software changes the review posture. You stop reading file by file and start reading system by system. You stop trusting local correctness as a proxy for safety. You try to prove the blast radius is small, or at least understood.
The outputs that actually help in practice are not abstract scores. They are concrete:
- direct and transitive dependents
- affected tests
- likely reviewers or owners
- public API exposure
- a risk tier with explanation
- dead code and low-confidence paths where reasoning gets shaky
That is how teams assess code change impact before merge. Dependency aware change analysis matters because local edits often have non-local effects. In big codebases, that is the default, not the exception.
Where AI-Generated Changes Fail Without Architectural Context
Most AI-generated failures don't look dramatic in the diff. The code often appears reasonable in isolation. The problem is that the assistant can't reliably see cross-file, cross-module, or cross-repo consequences unless you give it that context.
Maintenance work is the danger zone. Refactors and chores feel safer than feature work, so people review them with less tension. That's exactly where breaking changes slip through. Cleanups are where hidden coupling gets exposed.
A few failure modes come up again and again:
- changing a function signature with hidden callers
- renaming symbols referenced indirectly through strings, config, or code generation
- moving code across boundaries without preserving imports, ownership, or layering rules
- deleting "unused" code that's still invoked through reflection or runtime wiring
- changing exception handling so failures go soft and defects stay hidden
- touching generated or shared utility code with wide fan-out
One of the more expensive mistakes is deleting code too early. Dead-looking code and low-observability code are not the same thing. We've seen teams spend a day cleaning up a "clear win" only to spend the next two days restoring a path used by a migration job that runs once a month.
Large-scale evidence on AI-generated commits adds another layer. They regularly introduce code smells, correctness issues, and security issues, and a meaningful share of those issues remain in the repo instead of getting cleaned up quickly. The point isn't that AI is unusable. The point is that unchecked AI output creates maintenance drag that compounds.
The hard question is rarely "does it compile?" The hard question is "does it respect the real dependency graph of the system?"
The Core Questions to Ask Before You Accept an AI Suggestion
If you're going to use AI seriously, you need a decision checklist. Not a vibe check.
Start with these seven questions:
- What depends on the thing being changed?
Look for direct callers, transitive callers, external consumers, scheduled jobs, scripts, and tooling. Hidden consumers are where simple edits stop being simple. - Is this a contract change or an implementation change?
Public APIs, function signatures, event schemas, CLI flags, environment variables, and database expectations are high-risk surfaces. Internal implementation details usually give you more room. - Is the code truly dead, or just hard to trace?
Distinguish dead code from low-observability code. Keeping clutter for one more cycle is often cheaper than deleting the wrong path. - What tests just became mandatory?
Unit tests cover direct logic. Integration tests cover boundaries. End-to-end tests matter when critical workflows or contracts move. - Who should review this besides the author?
Pull in module owners, downstream service owners, and platform teams when shared abstractions are touched. The best reviewer is often not the person closest to the file. - What will failure look like if this breaks?
Compile-time failure is noisy. Runtime exceptions are catchable. Silent behavior drift, degraded performance, and fail-soft behavior are worse because they hide. - How certain is the analysis?
File-only analysis is weak. Semantic cross-reference analysis is stronger. Runtime evidence can raise confidence where static analysis can't fully resolve paths.
If you can't answer these seven, you don't understand the change yet.
That doesn't mean reject the AI suggestion. It means don't merge on instinct.
The Signals That Matter When You Assess Code Change Impact
Good impact analysis is built from signals you can inspect. Not a mysterious score and a green badge.
The useful inputs
Dependency and caller data tells you reach:
- number of direct callers
- transitive reach across modules
- whether the symbol is shared utility code or private implementation
Interface change data tells you fragility:
- signature changes
- parameter removals or reordering
- return type changes
- renamed exports
- deleted endpoints or events
Architectural position changes the meaning of the same edit. A two-line patch in a shared library can be riskier than a fifty-line patch in a leaf module. Internal services carry one profile. External-facing boundaries carry another. Hot paths deserve a different posture than rarely used paths.
Historical evidence helps too. Files that often change together, components with high churn, and areas with prior regressions are not random noise. They usually point to unstable seams.
Test coverage matters only if you can map it to affected areas. "We have lots of tests" is not useful if the change touches a path with weak integration coverage.
Ownership is another real signal. No clear owner means higher merge risk. Somebody needs to understand the blast radius.
Confidence matters as much as findings
A decent analysis should tell you what it knows and where it's guessing.
- static-only analysis has blind spots
- unresolved dynamic dispatch lowers confidence
- generated code and reflection-heavy frameworks are harder to reason about
Research suggests pull request level impact analysis can be computationally practical. You don't need a long pipeline step to get useful output. In many cases, seconds is enough.
Good engineering impact analysis tools should expose both findings and confidence. If a tool gives you one risk number with no explanation, it's asking for trust it hasn't earned.
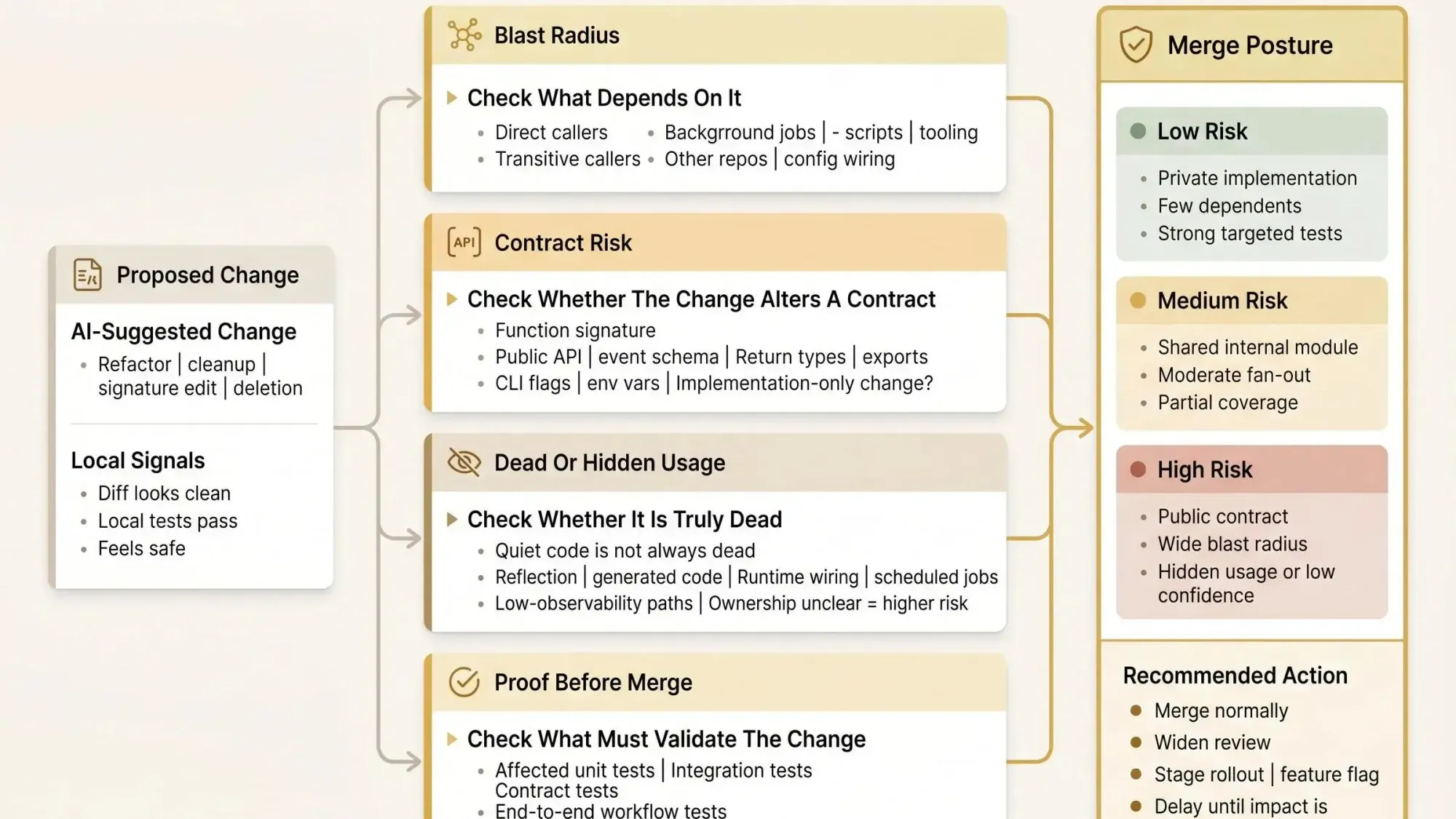
A Practical Workflow for Change Impact Analysis Before the PR Is Opened
The best time to run change impact analysis is before the patch hardens into a PR. Once the design is baked in, people defend it.
Here's a workflow that fits normal AI-assisted development.
- Start from the proposed change, not the diff alone
Ask the assistant which symbols, interfaces, and modules it plans to touch. Capture intended behavior, not just file edits. - Map direct and transitive dependencies
List callers, imports, references, and downstream consumers. Decide whether this is truly local or a shared contract in disguise. - Check dead code versus hidden code paths
Before deleting anything, inspect usage, ownership, and runtime entry points. - Classify the change type
Feature, bug fix, refactor, chore, migration. Maintenance categories deserve stricter scrutiny because harmless-looking edits often carry elevated breaking-change risk. - Estimate blast radius
How many modules, files, services, or repos could be affected? Are the affected areas internal, customer-facing, or infrastructure-critical? - Select tests intentionally
Run targeted tests for direct dependents. Escalate to integration or contract tests when interfaces move. - Route the review
Notify owners of affected modules. Pull in reviewers who understand downstream impact, not just the changed files. - Decide merge posture
Low-risk local change with tight tests is different from a high-risk contract change that needs staged rollout or a feature flag.
A concrete example: an assistant proposes extracting auth logic into a shared helper. The refactor looks cleaner. Impact analysis shows multiple downstream callers, shared test dependencies, and one deprecated path still in use. The right move is not rejecting the refactor. It's updating callers deliberately, tightening test selection, and widening review before merge.
That is real speed. Not blind speed.
Dependency Aware Change Analysis in Monorepos and Multi-Repo Systems
As systems scale, dependency aware change analysis gets harder and more necessary at the same time. More shared packages. More indirect references. More ownership boundaries. More ways for a local cleanup to become a platform change.
In monorepos, the main problem is fan-out. Shared modules can reach far wider than engineers expect, and test selection becomes critical if you want CI to stay useful.
In multi-repo systems, the problem shifts. Service contracts and package versions create coupling that's often invisible from one repo alone. Migration planning starts to matter as much as code correctness.
There is also an indexing quality problem that many teams ignore until the tool disappoints them.
- lightweight parsing can detect symbols quickly but has lower confidence for cross-file relationships
- semantic indexing gives better cross-reference accuracy when available
- runtime evidence helps where static analysis can't resolve the path cleanly
This matters for AI tools because an LLM working from prompt context cannot hold the full dependency graph of a large codebase in memory. That isn't a moral failure. It's just a limit. An external graph or impact system adds the missing layer.
Pharaoh approaches this by mapping the codebase into a knowledge graph so AI assistants can reason about dependencies, blast radius, existing code, and dead code before making changes. If you're using Claude Code, Cursor, Codex, or another MCP client, that's the kind of context layer that changes the conversation. More at pharaoh.so.
If your team works across multiple modules or repos, impact analysis is not extra process. It's the minimum context needed to make AI-assisted development trustworthy.
How to Predict Regression Risk From Code Changes Without Guesswork
The goal is not magic prediction. The goal is to predict regression risk from code changes using evidence engineers can inspect, argue with, and improve.
A useful model breaks risk into a few dimensions:
- severity if the change breaks
- exposure based on how widely the code is used
- confidence in the analysis
- uncertainty from dynamic behavior, generated code, or weak test mapping
A good risk model should consider whether the change touches public APIs or private implementation, the number of dependent modules and files, the quality of test coverage on affected areas, ownership clarity, historical churn, co-change patterns, and unresolved call paths.
Bad shortcuts are still common:
- lines changed is not enough
- agent confidence is not enough
- a green unit test suite is not enough for shared interfaces
Studies on impact-based review support show developers find it helpful, but risk scoring itself still needs calibration. That's the right way to think about it. Scores are decision support, not truth.
A simple severity model works well in practice:
- Low risk: private implementation, few dependents, strong targeted tests
- Medium risk: shared internal module, moderate fan-out, partial integration coverage
- High risk: public contract, many downstream consumers, low-confidence dependency resolution
You're not trying to predict every bug. You're trying to predict where local reasoning is most likely to fail.
Where Impact Analysis Belongs in PR Review, Test Selection, and Reviewer Routing
Software impact analysis works best when it's embedded in the workflow you already have.
In PR review, reviewers should read changed files plus affected dependents and likely side effects. A blast radius note in the PR description saves time immediately. It gives reviewers context in seconds instead of forcing them to reconstruct the system from scratch.
A good PR pattern includes:
- direct callers
- transitive reach
- affected tests
- co-change files
- readable risk summary
- likely owners or reviewers
Test selection should also be impact-based. Run the smallest meaningful set of tests based on affected code, especially in large repos where CI cost is real. Broad default suites waste time. Narrow local tests miss cross-boundary regressions. Both are common failure modes.
Reviewer routing is where many teams quietly lose the plot. The only reviewer is often the person who knows the edited file best and the consumers least. That's upside down. Reviewer suggestions should follow ownership boundaries and downstream dependencies.
Release planning belongs here too. Impact analysis should influence whether a change needs a feature flag, staged rollout, migration note, or extra observability.
If you care about code quality broadly, the open source AI Code Quality Framework covers the linting and testing side well at github.com/0xUXDesign/ai-code-quality-framework. Impact analysis complements that. It doesn't replace it.
What to Look for in Engineering Impact Analysis Tools
Don't shop for a product list. Evaluate the approach.
Core capabilities should include call graph or dependency analysis, API or signature diffing, affected test identification, history or co-change analysis, reviewer or ownership hints, and confidence indicators.
Output quality matters more than feature count. Ask:
- can the tool explain why a change is risky?
- does it surface blast radius in a form a human can act on?
- does it distinguish likely impact from confirmed usage?
Workflow fit is another filter. The tool should help before coding, during drafting, and in PR review. If it only shows up after the patch is written, some of the damage is already done. It should support AI-assisted workflows, not just post-hoc human review, and it should handle monorepos or multi-repo environments if that's your world.
Accuracy has tradeoffs. AST and tree-based extraction is fast and broad but may miss deeper semantic relationships. Semantic indexing improves cross-file resolution. Runtime tracing helps where static analysis has blind spots.
Different tools lean toward different research lines. Some focus on API stability and signature diffs. Some focus on PR risk scoring through call graphs and history mining. Some combine blast radius with test and reviewer suggestions.
For teams using Claude Code, Cursor, Codex, or other MCP clients, Pharaoh is useful when the main problem is giving the assistant architecture-level context instead of raw file snippets. That's a different category of help than a PR-only checker.
Choose based on codebase size, language mix, indexing maturity, and whether you need file-level hints or true system-level reasoning.
Common Mistakes Teams Make With Change Impact Analysis
Most failures here are process mistakes, not math mistakes.
Treating impact analysis as PR-only is the first one. By then, the wrong design choice may already be sitting in the patch.
Another is confusing unused code with dead code. Low-frequency and indirect usage often looks dead until production disagrees.
Teams also overtrust the wrong signals:
- AI confidence
- passing tests
- clean lint output
Those can all be true while contract or dependency breakage is still hiding.
A few more mistakes show up often:
- using a single opaque risk score without showing inputs
- ignoring maintenance work because it feels safer than feature work
- failing to distinguish static certainty from static guesswork
- running too many tests or too few
- keeping impact analysis detached from ownership
Knowing the blast radius is only useful if the right people see it before merge.
That's the operator view. Not every signal needs to be perfect, but it does need to be inspectable.
A Simple Adoption Plan for Teams Using AI Coding Assistants Today
You don't need a quarter-long initiative to start.
Week 1
Pick one active repo or service. Define your high-risk surfaces: public APIs, shared libraries, auth, billing, infrastructure, and data contracts. Add a lightweight pre-merge checklist focused on blast radius.
Week 2
Require impact notes in AI-assisted PRs. Keep it short:
- direct dependents
- affected tests
- contract changes
- owner mentions
Week 3
Add tool support where it helps most. Start with dependency and caller analysis for shared code. Improve test mapping for common regression areas.
Week 4
Review the last few AI-assisted changes that caused surprises. Ask which impact signals would have caught them earlier. Then make those signals part of the default workflow.
A few team norms are worth adopting early:
- stricter review posture for refactors and chores
- no deletion without usage evidence
- no contract change without downstream check
- no risk score without explanation
If you're already using Claude Code or another MCP client, adding an architecture graph can be a fast way to give the assistant system context instead of file context. In practice, that changes the first session.
Conclusion
Safer AI-assisted development does not come from slowing down or distrusting every suggestion. It comes from seeing the system around the change.
Software impact analysis helps you assess code change impact before merge. Dependency aware change analysis matters most in shared code and maintenance-heavy work, where the patch often looks smaller than the risk. The best way to predict regression risk from code changes is to combine dependency data, contract awareness, test mapping, ownership, and confidence signals.
On your next AI-assisted PR, add a short impact section covering dependents, affected tests, contract changes, and likely reviewers. Start there.
If your team lacks that context today, add an architecture graph so both humans and AI can reason from the codebase as a system, not a pile of files. Pharaoh does this automatically via MCP at pharaoh.so.